

Functional Database Concept


The database world has long been taken over by relational DBMSs that use the SQL language. So much so that all alternatives are called NoSQL. They managed to win back a certain place in this market, but relational DBMSs are not going to die, and continue to be actively used for their purposes.
In this article, I want to describe the concept of a functional database. For better understanding, I will do this by comparing it to the classical relational model. The examples will be tasks from various SQL exercises found on the Internet.
Introduction
Relational databases operate with tables and fields. In a functional database, classes and functions will be used instead, respectively. A field in a table with N keys will be represented as a function of N parameters. Instead of relations between tables, functions that return objects of the class to which the relation goes will be used. Instead of JOIN a composition of functions will be used.
Before I go directly to the tasks, I will describe the definition of the domain logic. For the DDL I will use PostgreSQL syntax. For the functional one I will use my own syntax.
Tables and fields
A simple Sku object with name and price field:
Relational
CREATE TABLE Sku
(
id bigint NOT NULL,
name character varying(100),
price numeric(10,5),
CONSTRAINT id_pkey PRIMARY KEY (id)
)
Functional
CLASS Sku;
name = DATA STRING[100] (Sku);
price = DATA NUMERIC[10,5] (Sku);
We declare two functions that take as input one parameter Sku, and return a primitive type.
It is assumed that each object in the functional database will have some internal code that is automatically generated and can be accessed if needed.
Let's set a price for a product / store / supplier. It can change over time, so let's add to the table the field time. I will skip the declaration of tables for the tables in the relational database to reduce the code:
Relational
CREATE TABLE prices
(
skuId bigint NOT NULL,
storeId bigint NOT NULL,
supplierId bigint NOT NULL,
dateTime timestamp without time zone,
price numeric(10,5),
CONSTRAINT prices_pkey PRIMARY KEY (skuId, storeId, supplierId)
)
Functional
CLASS Sku;
CLASS Store;
CLASS Supplier;
dateTime = DATA DATETIME (Sku, Store, Supplier);
price = DATA NUMERIC[10,5] (Sku, Store, Supplier);
Indexes
Finally, we build an index for all the keys and the date, so we can quickly find the price at a certain time.
Relational
CREATE INDEX prices_date
ON prices
(skuId, storeId, supplierId, dateTime)
Functional
INDEX sku sk, Store st, Supplier sp, dateTime(sk, st, sp);
Tasks
Let's start with relatively simple examples. First let's declare the domain logic as follows (employees and departments) :
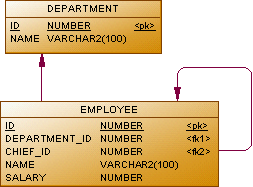
Functional
CLASS Department;
name = DATA STRING[100] (Department);
CLASS Employee;
department = DATA Department (Employee);
name = DATA STRING[100] (Employee);
salary = DATA NUMERIC[14,2] (Employee);
Task 1.1.
Select a list of employees that are paid more than their immediate chief's salary.
select a.*
from employee a
where a.salary = ( select max(salary) from employee b
where b.department_id = a.department_id )
SELECT name(Employee a) WHERE salary(a) > salary(chief(a));
Task 1.2.
Select a list of employees that have the maximum salary in their department.
select a.*
from employee a
where a.salary = ( select max(salary) from employee b
where b.department_id = a.department_id )
maxSalary (Department s) =
GROUP MAX salary(Employee e) IF department(e) = s;
SELECT name(Employee a) WHERE salary(a) = maxSalary(department(a));
//or "inline"
SELECT name(Employee a) WHERE
salary(a) = maxSalary(GROUP MAX salary(Employee e) IF department(e) = department(a));
These two implementations are equivalent. For the first case, you can use CREATE VIEW in a relational database, which will first calculate the maximum salary for a specific department in the same way. In the future, I will use the first case for clarity, because it better shows the solution.
Task 1.3.
Select a list of IDs of the departments that do not have more than 3 employees.
select department_id
from employee
group by department_id
having count(*) <= 3
countEmployees (Department d) =
GROUP SUM 1 IF department(Employee e) = d;
SELECT Department d WHERE countEmployees(d) <= 3;
Task 1.4.
Select a list of employees that do not have an assigned chief working in the same department.
select a.*
from employee a
left join employee b on (b.id = a.chief_id and b.department_id = a.department_id)
where b.id is null
SELECT name(Employee a) WHERE NOT (department(chief(a)) = department(a));
Task 1.5.
Find a list of department IDs with the maximum total salary of employees.
with sum_salary as
( select department_id, sum(salary) salary
from employee
group by department_id )
select department_id
from sum_salary a
where a.salary = ( select max(salary) from sum_salary )
salarySum (Department d) =
GROUP SUM salary(Employee e) IF department(e) = d;
maxSalarySum () = GROUP MAX salarySum(Department d);
SELECT Department d WHERE salarySum(d) = maxSalarySum();
Now, let's proceed to more complex tasks. Consider the following domain logic :

Functional definition (part needed for the following example) :
CLASS Employee;
lastName = DATA STRING[100] (Employee);
CLASS Product;
id = DATA INTEGER (Product);
name = DATA STRING[100] (Product);
CLASS Order;
date = DATA DATE (Order);
employee = DATA Employee (Order);
CLASS Detail;
order = DATA Order (Detail);
product = DATA Product (Detail);
quantity = DATA NUMERIC[10,5] (Detail);
Task 2.1.
Which employees sold more than 30 pieces of product #1 in 1997?
select LastName
from Employees as e
where (
select sum(od.Quantity)
from [Order Details] as od
where od.ProductID = 1 and od.OrderID in (
select o.OrderID
from Orders as o
where year(o.OrderDate) = 1997 and e.EmployeeID = o.EmployeeID)
) > 30
sold (Employee e, INTEGER productId, INTEGER year) =
GROUP SUM quantity(OrderDetail d) IF
employee(order(d)) = e AND
id(product(d)) = productId AND
extractYear(date(order(d))) = year;
SELECT lastName(Employee e) WHERE sold(e, 1, 1997) > 30;
Task 2.2.
For each customer, find the two products for which the customer spent the most money in 1997.
Let's extend the domain logic from the previous example:
CLASS Customer;
contactName = DATA STRING[100] (Customer);
customer = DATA Customer (Order);
unitPrice = DATA NUMERIC[14,2] (Detail);
discount = DATA NUMERIC[6,2] (Detail);
Solution :
SELECT ContactName, ProductName FROM (
SELECT c.ContactName, p.ProductName
, ROW_NUMBER() OVER (
PARTITION BY c.ContactName
ORDER BY SUM(od.Quantity * od.UnitPrice * (1 - od.Discount)) DESC
) AS RatingByAmt
FROM Customers c
JOIN Orders o ON o.CustomerID = c.CustomerID
JOIN [Order Details] od ON od.OrderID = o.OrderID
JOIN Products p ON p.ProductID = od.ProductID
WHERE YEAR(o.OrderDate) = 1997
GROUP BY c.ContactName, p.ProductName
) t
WHERE RatingByAmt < 3
sum (Detail d) = quantity(d) * unitPrice(d) * (1 - discount(d));
bought (Customer c, Product p, INTEGER y) =
GROUP SUM sum(Detail(d) IF
customer(order(d)) = c AND
product(d) = p AND
extractYear(date(order(d))) = y;
rating (Customer c, Product p, INTEGER y) =
PARTITION SUM 1 ORDER DESC bought(c, p, y), p
BY c, y;
SELECT contactName(Customer c), name(Product p) WHERE rating(c, p, 1997) < 3;
The PARTITION operator works according to the following principle: it sums up the expression specified after SUM (here 1) inside the specified groups (here Customer and Year, but it can be any expression), sorting inside the groups by the expressions specified in ORDER.
Task 2.3.
How many products need to be ordered from suppliers to fulfill the current orders.
Again we expand the domain logic:
CLASS Supplier;
companyName = DATA STRING[100] (Supplier);
supplier = DATA Supplier (Product);
unitsInStock = DATA NUMERIC[10,3] (Product);
reorderLevel = DATA NUMERIC[10,3] (Product);
Solution :
select s.CompanyName, p.ProductName, sum(od.Quantity) + p.ReorderLevel - p.UnitsInStock as ToOrder
from Orders o
join [Order Details] od on o.OrderID = od.OrderID
join Products p on od.ProductID = p.ProductID
join Suppliers s on p.SupplierID = s.SupplierID
where o.ShippedDate is null
group by s.CompanyName, p.ProductName, p.UnitsInStock, p.ReorderLevel
having p.UnitsInStock < sum(od.Quantity) + p.ReorderLevel
orderedNotShipped (Product p) =
GROUP SUM quantity(OrderDetail d) IF product(d) = p;
toOrder (Product p) = orderedNotShipped(p) + reorderLevel(p) - unitsInStock(p);
SELECT companyName(supplier(Product p)), name(p), toOrder(p) WHERE toOrder(p) > 0;
A task with an asterisk
And one last example. There is a "social network" logic. People can be friends with each other and like each other. In terms of a functional database, this would look like this:
CLASS Person;
likes = DATA BOOLEAN (Person, Person);
friends = DATA BOOLEAN (Person, Person);
We need to find possible friendship candidates. More formally, we need to find all people A, B, C such that A is friends with B and B is friends with C, A likes C, but A is not friends with C. In terms of a functional database, the query would look like this:
SELECT Person a, Person b, Person c WHERE
likes(a, c) AND NOT friends(a, c) AND
friends(a, b) AND friends(b, c);
It is assumed that there are far fewer friends than likes. Therefore they are stored in separate tables. There is also a problem with two asterisks. In it the friendship is not symmetric. On a functional database it will look like this:
SELECT Person a, Person b, Person c WHERE
likes(a, c) AND NOT friends(a, c) AND
(friends(a, b) OR friends(b, a)) AND
(friends(b, c) OR friends(c, b));
In relational logic, I won't give you the SQL query because it would be much more complicated and take up a lot of space.
Conclusion
It should be noted that the above mentioned language syntax is just one of the options for implementing the above concept. SQL was taken as the basis and the goal was to make it as similar to it as possible. Of course, some may not like the names of keywords, word registers, etc. What matters here is the concept itself. It is possible to make both C++ and Python similar syntax.
The described database concept, in my opinion, has the following advantages:
Simplicity. This is a relatively subjective metric that is not obvious on simple cases. But if we look at more complex cases (for example, tasks with asterisks), it is much easier, in my opinion, to write such queries.
Encapsulation. In some examples, I declared intermediate functions (e.g. sold, bought, etc.), from which subsequent functions were built. This allows you to change the logic of certain functions, if necessary, without changing the logic of the functions that depend on them. For example, you can make sold count from completely different objects, without changing the rest of the logic. Yes, you can do that with CREATE VIEW in RDBMS. But if all logic is written this way, it won't look very readable.
No semantic gap. Such a database operates with functions and classes (instead of tables and fields). Exactly as in classical programming (if we consider that a method is a function with the first parameter as the class to which it refers). Accordingly, it should be much easier to "friend" with universal programming languages. In addition, this concept allows you to implement much more complex functions. For example, you can embed operators like:
CONSTRAINT sold(Employee e, 1, 2019) > 100
IF name(e) = 'John'
MESSAGE 'John sells too many products in 2019';
- Inheritance and polymorphism. In a functional database, you can introduce multiple inheritance through
CLASS ClassP: Class1, Class2constructs and implement multiple polymorphism.
Despite the fact that this is just a concept, there is already an implementation in Java which translates all the functional logic into relational logic. It also implements the user interface logic, and much more, making it a whole platform. It uses RDBMS (so far only PostgreSQL) as a "virtual machine". However, in theory, it is possible to implement a database management system, which will use as a storage structure, adapted specifically to the functional logic.